Posts Tagged ‘statistics’
The Mathematics of Changing Your Mind
06
Aug
The controversial history of the mathematical theorem that tells us when we should change our minds.

Drupal contributor statistics
06
Jun
I recently extracted some data from the Drupal project's CVS and Git logs to see how the number of code contributors and total contributions have changed over time. If there was any doubt of our continual growth, the resulting charts demolish it.
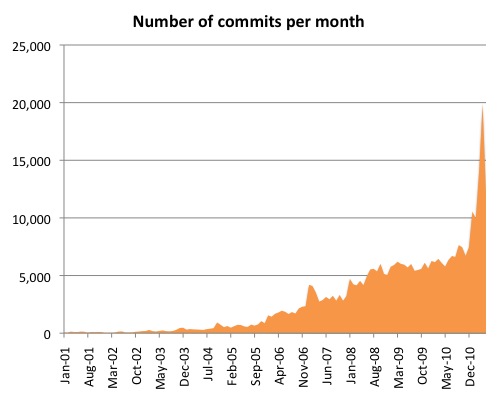
Aggregated results from core and contributed modules.
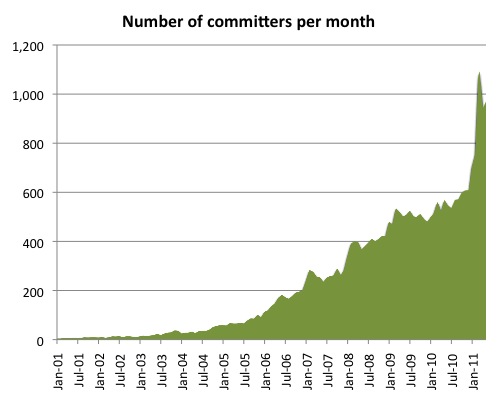
Aggregated results from core and contributed modules.
As can be seen from the graphs, there is a pretty big spike in commit activity post-Git migration.
jStat – A Statistical Library With JavaScript
10
Apr
jStat is a JavaScript library which enables you to perform advanced statistical operations without the need of a dedicated statistical language.
Simply, it focuses on being a real JavaScript-based alternative for languages like R and MATLAB.
The library is standalone, however, for the plotting functionality, it requires jQuery, jQuery UI and jQuery-flot plugin.

Special Downloads:
Ajaxed Add-To-Basket Scenarios With jQuery And PHP
Free Admin Template For Web Applications
jQuery Dynamic Drag’n Drop
ScheduledTweets
Advertisements:
Professional XHTML Admin Template ($15 Discount With The Code: WRD.)
Psd to Xhtml
SSLmatic – Cheap SSL Certificates (from $19.99/year)
The Unprecedented Rise of Apple iOS and Other Internet Trends [STATS]
16
Nov





Legendary Internet analyst Mary Meeker has some statistics she thinks every Internet executive should know, including that iOS is growing faster than almost any other Internet technology in history.
At the Web 2.0 Summit in San Francisco, the Morgan Stanley analyst led a rapid-pace presentation on the state of the Internet industry, revealing the state of mobile (Apple and Google are winning), the most under-monetized asset in online advertising (Facebook) and even the secret sauce of Steve Jobs (he has the mind of an engineer and the heart of an artist).
Some of Meeker’s eye-popping stats:
- 46% of Internet users live in five countries: the USA, Russia, Brazil, China and India.
- There are 670 million 3G subscribers worldwide, 136.6 million in the U.S. and 106.3 million in Japan.
- iOS devices reached 120 million subscribers in 13 quarters, far faster than Netscape, AOL or NTT docomo’s growth rates.
- Nokia and Symbian used to own 62% of the smartphone market (units shipped). Now it’s only 37%, mostly due to Android and iOS.
- The average CPM for social networking sites is at only $0.55. Meeker thinks this will increase and normalize in the next few years. She also believes that inventory on Facebook is one of the most under-monetized assets on the web.
- It took e-commerce 15 years to get to 5% of retail. Morgan Stanley predicts mobile should get to that same level in five years.
- Streaming video is up to 37% of of Internet traffic during traditional “TV hours.†Netflix is the biggest contributor to this, followed by YouTube.
- Seven of the companies that were in the top 15 publicly traded Internet companies in 2004 are not in that list in 2010.
- Interest payments and entitlement spending is projected to exceed government revenue by 2025. In other words, the U.S. government is facing a real financial crisis soon.
We’ve included Mary Meeker’s full presentation below. Let us know what you think of her statistics and trends in the comments.
Reviews: Android, Facebook, Google, Internet, YouTube
More About: apple, internet, Internet trends, iOS, Mary Meeker, Morgan Stanley, statistics, stats, steve jobs, W2S2010, Web 2.0 Summit
For more Business coverage:
- Follow Mashable Business on Twitter
- Become a Fan on Facebook
- Subscribe to the Business channel
- Download our free apps for iPhone and iPad
Twitter API Calls Doubled Since April: Now Serving 70,000 Every Second
16
Sep
 Have you ever wondered how much traffic Twitter handles in a given day, or what software sits behind the curtain of the popular service? A recent presentation reveals some of the answers. Twitter’s incredible growth becomes obvious when you compare the recent numbers to those announced at Chirp.
Have you ever wondered how much traffic Twitter handles in a given day, or what software sits behind the curtain of the popular service? A recent presentation reveals some of the answers. Twitter’s incredible growth becomes obvious when you compare the recent numbers to those announced at Chirp.

On September 9th, Twitter’s university recruiting team stopped by UC Berkeley to talk about the company and what it does. The slides from platform engineer Raffi Krikorian’s talk, Twitter by the Numbers, are now online, and they disclose some fascinating technical details about the social media giant’s operations.
Twitter serves over 70 million tweets per day, totaling over 12GB of tweet text alone. Many of those messages are delivered to client apps and web sites through the Twitter API to the tune of six billion API calls per day (double what was announced at Chirp in April), or about 70,000 API calls per second. All told, the service generates 8TB of data every day, which is eight times more than the New York Stock Exchange.

Pop quiz, engineers: Your web service needs to deliver real-time message traffic to an asymmetric digraph of over 150 million users. What database do you use? WHAT DATABASE DO YOU USE?
- Shoot the hostage
- Oracle
- MySQL
- Write your own database
If you’re Twitter, the correct answer is #4: Create your own database software, call it FlockDB, and release it on github. (By the way, if you picked option 1, maybe software engineering isn’t the right career choice for you.)
FlockDB is just one of the home-grown, high-performance software systems Twitter uses to support its tremendous growth. Others include:
- hosebird, a “near real-time†streaming API back-end (instead of REST, which is only “pseudo real-timeâ€); and
- snowflake (also on github), a network service to generate unique IDs at high scale (MySQL couldn’t keep up, and was a single point of failure).
With a stated goal of supporting “half the world and all its devices,†Twitter faces many engineering challenges. This peek under the hood (full slides are embedded below) shows that they’re aware of the potential problems, and are working hard to steer clear of the fail whale.