
Posts Tagged ‘Search’
Google Flights Search Is a Powerful, Intuitive, Lightning-Fast Tool for Finding Cheap Tickets
13
Sep
How Schema.org Will Change Your Search Results & What it Means for Marketers
30
Jun





Jeff Ente is the director of Who’s Blogging What, a weekly e-newsletter that tracks over 1,100 social media, web marketing and user experience blogs to keep readers informed about key developments in their field and highlight useful but hard to find posts. Mashable readers can subscribe for free here.
Algorithms aren’t going away anytime soon now that websites have a better way to directly describe their content to major search engines. Earlier this month, Google, Bing and Yahoo came together to announce support for Schema.org, a semantic markup protocol with its own vocabulary that could provide websites with valuable search exposure. Nothing will change overnight, but Schema.org is important enough to bring the three search giants together. Websites would be wise to study the basics and come up with a plan to give the engines what they want.
Schema.org attempts to close a loophole in the information transfer from website data to presentation as search results. As they note on their homepage: “Many sites are generated from structured data, which is often stored in databases. When this data is formatted into HTML, it becomes very difficult to recover the original structured data.â€
Simply put, Schema.org hopes to create a uniform method of putting the structure back into the HTML where the spiders can read it. The implications go beyond just knowing if a keyword like “bass†refers to a fish, a musical instrument or a brand of shoes. The real value is that websites can provide supporting data that will be valuable to the end user, and they can do so in a way that most search engines can read and pass along.
How Schema.org Works
Schema.org was born out of conflict between competing standards. Resource Description Framework (RDF) is the semantic standard accepted by The World Wide Web Consortium (W3C). The Facebook Open Graph is based on a variant of RDF which was one reason that RDF seemed poised to emerge as the dominant standard.
Until this month. Schema.org went with a competing standard called microdata which is part of HTML5.
Microdata, true to its name, embeds itself deeply into the HTML. Simplicity was a key attribute used by the search engines to explain their preference for microdata, but simplicity is a relative term. Here is a basic example of how microdata works:
<div itemscope itemtype="http://data-vocabulary.org/Person">
<span itemprop="name">Abraham Lincoln</span> was born on
<span itemprop="birthDate">Feb. 12, 1809</span>.
He became known as <span itemprop="nickname">Honest Abe</span> and later served as <span itemprop="jobTitle">President of the United States</span>.
Tragically, he was assassinated and died on <span itemprop="deathDate">April 15, 1865</span>.
</div>
A machine fluent in Microdata would rely on three main attributes to understand the content:
- Itemscope delineates the content that is being described.
- Itemtype classifies the type of “thing†being described, in this case a person.
- Itemprop provides details about the person, in this case birth date, nickname, job title and date of death.
Meanwhile, a person would only see:
“Abraham Lincoln was born on Feb. 12, 1809. He became known as Honest Abe and later served as President of the United States. Tragically, he was assassinated and died on April 15, 1865.â€
Fast forward to the web economy of 2011 and restaurants can use the same technology to specify item properties such as acceptsReservations, menu, openingHours, priceRange, address and telephone.
A user can compare menus from nearby inexpensive Japanese restaurants that accept reservations and are open late. Schema.org’s vocabulary already describes a large number of businesses, from dentists to tattoo parlors to auto parts stores.
Examples of Structured Data Already in Use
Structured data in search results is not new. The significance of Schema.org is that it is now going to be available on a mass scale. In other words, semantic markup in HTML pages is going prime time.
Google has so far led the way with structured data presentation in the form of “rich snippets,†which certain sites have been using to enhance their search listings with things like ratings, reviews and pricing. Google began the program in May 2009 and added support for microdata in March 2010.
A well known example of a customized structured search presentation is Google Recipe View. Do you want to make your own mango ice cream, under 100 calories, in 15 minutes? Recipe View can tell you how.
The Scary Side of Schema.org
Google, Bing and Yahoo have reassured everyone that they will continue to support the other standards besides microdata, but Schema.org still feels like an imposed solution. Some semantic specialists are asking why the engines are telling websites to adapt to specific standards when perhaps it should be the other way around.
Another concern is that since Schema.org can be abused, it will be abused. That translates into some added work and expense as content management systems move to adapt.
Schema.org might also tempt search engines to directly answer questions on the results page. This will eliminate the need to actually visit the site that helped to provide the information. Publishing the local weather or currency conversion rate on a travel site won’t drive much traffic because search engines provide those answers directly. Schema.org means that this practice will only expand.
Not everyone is overly concerned about this change. “If websites feel ‘robbed’ of traffic because basic information is provided directly in the search results, one has to ask just how valuable those websites were to begin with,†notes Aaron Bradley who has blogged about Schema.org as the SEO Skeptic.
“The websites with the most to lose are those which capitalize on long-tail search traffic with very precise but very thin content,†Bradley says. “Websites with accessible, well-presented information and — critically — mechanisms that allow conversations between marketers and consumers to take place will continue to fare well in search.â€
Three Things To Do Right Now
- Audit the data that you store about the things that you sell. Do you have the main sales attributes readily available in machine readable form? Make sure you have the size, color, price, previous feedback, awards, etc. easily readable.
- Review the data type hierarchy currently supported by Schema.org to see where your business fits in and the types of data that you should be collecting.
- Check your content management and web authoring systems to see if they support microdata or if they are at least planning for it. Microdata is not just a few lines of code that go into the heading of each page. It needs to be written into the HTML at a very detailed level. For some site administrators it will be a nightmare, but for others who have done proper planning and have selected the right tools, it could become an automatic path to greater search exposure.
Image courtesy of iStockphoto, claudiobaba
More About: bing, business, Google, MARKETING, Schema, schema.org, Search, SEM, SEO, Yahoo
For more Dev & Design coverage:
- Follow Mashable Dev & Design on Twitter
- Become a Fan on Facebook
- Subscribe to the Dev & Design channel
- Download our free apps for Android, Mac, iPhone and iPad
Microsoft’s Bing uses Google search results—and denies it
01
Feb
By now, you may have read Danny Sullivan’s recent post: “Google: Bing is Cheating, Copying Our Search Results†and heard Microsoft’s response, “We do not copy Google's results.†However you define copying, the bottom line is, these Bing results came directly from Google.
I’d like to give you some background and details of our experiments that lead us to understand just how Bing is using Google web search results.
It all started with tarsorrhaphy. Really. As it happens, tarsorrhaphy is a rare surgical procedure on eyelids. And in the summer of 2010, we were looking at the search results for an unusual misspelled query [torsorophy]. Google returned the correct spelling—tarsorrhaphy—along with results for the corrected query. At that time, Bing had no results for the misspelling. Later in the summer, Bing started returning our first result to their users without offering the spell correction (see screenshots below). This was very strange. How could they return our first result to their users without the correct spelling? Had they known the correct spelling, they could have returned several more relevant results for the corrected query.
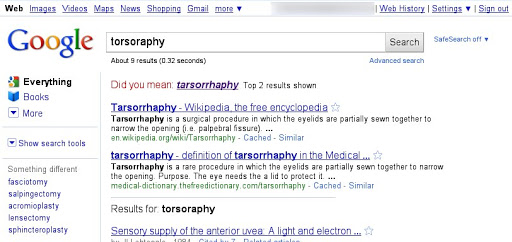
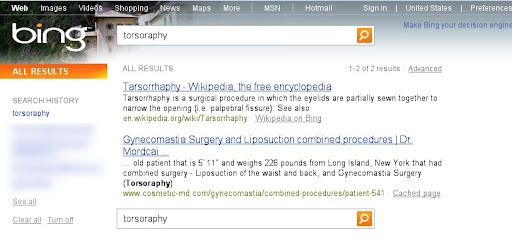
This example opened our eyes, and over the next few months we noticed that URLs from Google search results would later appear in Bing with increasing frequency for all kinds of queries: popular queries, rare or unusual queries and misspelled queries. Even search results that we would consider mistakes of our algorithms started showing up on Bing.
We couldn’t shake the feeling that something was going on, and our suspicions became much stronger in late October 2010 when we noticed a significant increase in how often Google’s top search result appeared at the top of Bing’s ranking for a variety of queries. This statistical pattern was too striking to ignore. To test our hypothesis, we needed an experiment to determine whether Microsoft was really using Google’s search results in Bing’s ranking.
We created about 100 “synthetic queriesâ€â€”queries that you would never expect a user to type, such as [hiybbprqag]. As a one-time experiment, for each synthetic query we inserted as Google’s top result a unique (real) webpage which had nothing to do with the query. Below is an example:

To be clear, the synthetic query had no relationship with the inserted result we chose—the query didn’t appear on the webpage, and there were no links to the webpage with that query phrase. In other words, there was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank.
We gave 20 of our engineers laptops with a fresh install of Microsoft Windows running Internet Explorer 8 with Bing Toolbar installed. As part of the install process, we opted in to the “Suggested Sites†feature of IE8, and we accepted the default options for the Bing Toolbar.
We asked these engineers to enter the synthetic queries into the search box on the Google home page, and click on the results, i.e., the results we inserted. We were surprised that within a couple weeks of starting this experiment, our inserted results started appearing in Bing. Below is an example: a search for [hiybbprqag] on Bing returned a page about seating at a theater in Los Angeles. As far as we know, the only connection between the query and result is Google’s result page (shown above).
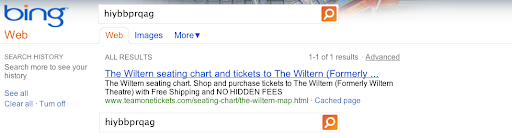
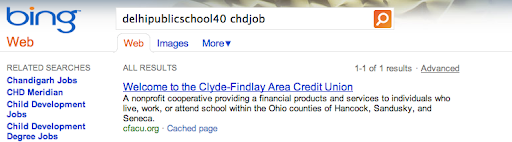
We saw this happen for multiple queries. For the query [delhipublicschool40 chdjob] we inserted a search result for a credit union:
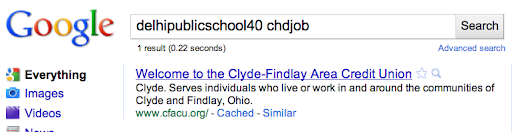
The same credit union soon showed up on Bing for that query:
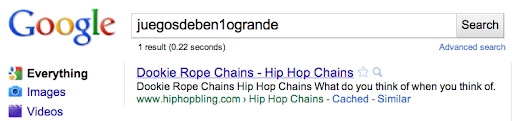
For the query [juegosdeben1ogrande] we inserted a page of hip hop bling jewelry:
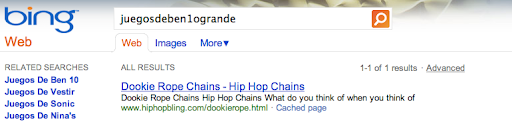
And the same hip hop bling page showed up in Bing:
As we see it, this experiment confirms our suspicion that Bing is using some combination of:
At Google we strongly believe in innovation and are proud of our search quality. We’ve invested thousands of person-years into developing our search algorithms because we want our users to get the right answer every time they search, and that’s not easy. We look forward to competing with genuinely new search algorithms out there—algorithms built on core innovation, and not on recycled search results from a competitor. So to all the users out there looking for the most authentic, relevant search results, we encourage you to come directly to Google. And to those who have asked what we want out of all this, the answer is simple: we'd like for this practice to stop.
Posted by Amit Singhal, Google Fellow




I’d like to give you some background and details of our experiments that lead us to understand just how Bing is using Google web search results.
It all started with tarsorrhaphy. Really. As it happens, tarsorrhaphy is a rare surgical procedure on eyelids. And in the summer of 2010, we were looking at the search results for an unusual misspelled query [torsorophy]. Google returned the correct spelling—tarsorrhaphy—along with results for the corrected query. At that time, Bing had no results for the misspelling. Later in the summer, Bing started returning our first result to their users without offering the spell correction (see screenshots below). This was very strange. How could they return our first result to their users without the correct spelling? Had they known the correct spelling, they could have returned several more relevant results for the corrected query.

We couldn’t shake the feeling that something was going on, and our suspicions became much stronger in late October 2010 when we noticed a significant increase in how often Google’s top search result appeared at the top of Bing’s ranking for a variety of queries. This statistical pattern was too striking to ignore. To test our hypothesis, we needed an experiment to determine whether Microsoft was really using Google’s search results in Bing’s ranking.
We created about 100 “synthetic queriesâ€â€”queries that you would never expect a user to type, such as [hiybbprqag]. As a one-time experiment, for each synthetic query we inserted as Google’s top result a unique (real) webpage which had nothing to do with the query. Below is an example:
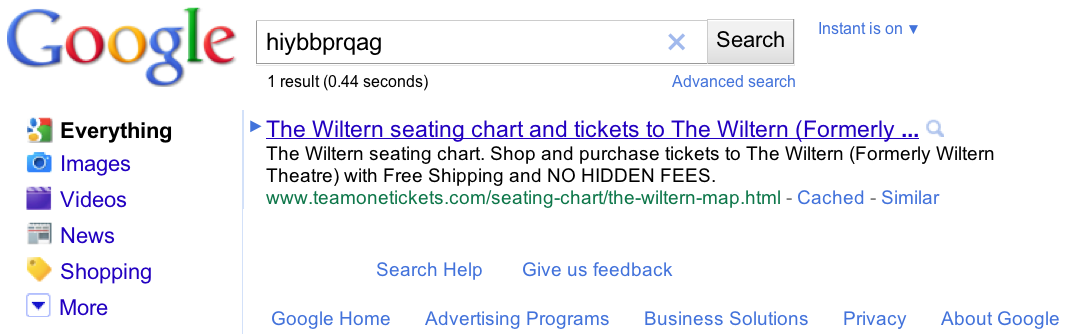
To be clear, the synthetic query had no relationship with the inserted result we chose—the query didn’t appear on the webpage, and there were no links to the webpage with that query phrase. In other words, there was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank.
We gave 20 of our engineers laptops with a fresh install of Microsoft Windows running Internet Explorer 8 with Bing Toolbar installed. As part of the install process, we opted in to the “Suggested Sites†feature of IE8, and we accepted the default options for the Bing Toolbar.
We asked these engineers to enter the synthetic queries into the search box on the Google home page, and click on the results, i.e., the results we inserted. We were surprised that within a couple weeks of starting this experiment, our inserted results started appearing in Bing. Below is an example: a search for [hiybbprqag] on Bing returned a page about seating at a theater in Los Angeles. As far as we know, the only connection between the query and result is Google’s result page (shown above).
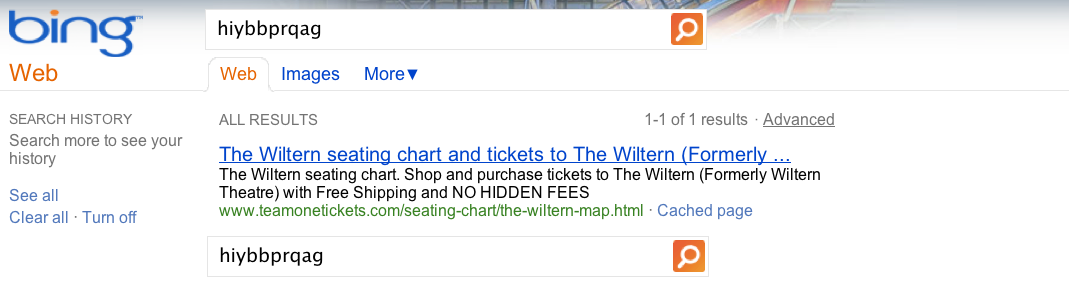
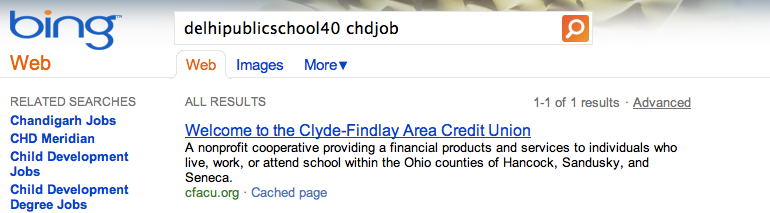
We saw this happen for multiple queries. For the query [delhipublicschool40 chdjob] we inserted a search result for a credit union:

The same credit union soon showed up on Bing for that query:
For the query [juegosdeben1ogrande] we inserted a page of hip hop bling jewelry:

And the same hip hop bling page showed up in Bing:

As we see it, this experiment confirms our suspicion that Bing is using some combination of:
- Internet Explorer 8, which can send data to Microsoft via its Suggested Sites feature
- the Bing Toolbar, which can send data via Microsoft’s Customer Experience Improvement Program
At Google we strongly believe in innovation and are proud of our search quality. We’ve invested thousands of person-years into developing our search algorithms because we want our users to get the right answer every time they search, and that’s not easy. We look forward to competing with genuinely new search algorithms out there—algorithms built on core innovation, and not on recycled search results from a competitor. So to all the users out there looking for the most authentic, relevant search results, we encourage you to come directly to Google. And to those who have asked what we want out of all this, the answer is simple: we'd like for this practice to stop.
Posted by Amit Singhal, Google Fellow
Google already knows its search sucks (and is working to fix it)
12
Jan
 It’s a popular notion these days Google has lost its “mojo†due to failed products like Google Wave, Google Buzz, and Google TV. But Google’s core business — Web search — has come under fire recently for being the ultimate in failed tech products.
It’s a popular notion these days Google has lost its “mojo†due to failed products like Google Wave, Google Buzz, and Google TV. But Google’s core business — Web search — has come under fire recently for being the ultimate in failed tech products.
I can only ask: What took so long? I first blogged about Google’s increasingly terrible search results in October 2007. If you search for any topic that is monetizable, such as “iPod Connectivity†or “Futon Fillingâ€, you will see pages and pages of search results selling products and very few that actually answer your query. In contrast, if you search for something that isn’t monetizable, say “bridge construction,†it is like going 10 years back into a search time machine.
Search has been increasingly gamed by link and content farms year by year, and users have been frogs slowly getting boiled in water without realizing it. (Bing has similarly bad results, a testament to Microsoft’s quest to copy everything Google.)
But here’s what these late-blooming critics miss: Yes, Google’s search results do indeed suck. But Google’s fixing it.
The much acclaimed PageRank algorithm, which ranks search results based on the highest number of inbound links, has failed since it’s easy for marketers to overwhelm the number of organic links with a bunch of astroturfed links. Case in point: The Google.com page that describes PageRank is #4 in the Google search results for the term PageRank, below two vendors that are selling search engine marketing.
Facebook, which can rank content based on the number of Likes from actual people rather than the number of inbound links from various websites, can now provide more relevant hits, and in realtime since it does not have to crawl the web. A Like is registered immediately. No wonder Facebook scares Google.
But the secret to Google’s success was actually not PageRank, although it makes for a good foundation myth. The now-forgotten AltaVista, buried within Yahoo and due to be shut down, actually returned great results by employing the exact opposite of PageRank, and returned pages that were hubs and had links to related content.
Google’s secret was that it could scale infinitely on low-cost hardware and was able to keep up with the Internet’s exponential growth, while its competitors such as AltaVista were running on expensive, big machines running processors like the DEC Alpha. When the size of the Web doubled, Google could cheaply keep up on commodity PC hardware, and AltaVista was left behind. Cheap and expandable computing, not ranking Web pages, is what Google does best. Combine that with an ever-expanding data set, based on people’s clicks, and you have a virtuous circle that keeps on spinning.
The folks at Google have not been asleep at the wheel. They are well aware that their search results were being increasingly gamed by search marketers and that this was not a battle they were going to win. The answer has been to dump the famous blue links on which Google built its business.
Over the past couple of years, Google has progressively added vertical search results above its regular results. When you search for the weather, businesses, stock quotes, popular videos, music, addresses, airplane flight status, and more, the search results of what you are looking for are presented immediately. The vast majority of users are no longer clicking through pages of Google results: They are instantly getting an answer to their question:

Google is in the unique position of being able to learn from billions and billions of queries what is relevant and what can be verticalized into immediate results. Google’s search value proposition has now transitioned to immediately answering your question, with the option of sifting through additional results. And that’s through a combination of computing power and accumulated data that competitors just can’t match.
For those of us who have watched this transition closely and attentively over the past few years, it has been an amazing feat that should be commended. So while I am the first to make fun of Google’s various product failures, Google search is no longer one of them.
Tags: PageRank, search, search engine optimization, search-engine marketings, SEO
Companies: Google
People: Peter Yared
Use the AROUND Operator in Google Searches for More Specific Results [Google Search]
07
Dec

Buddy Media Gives Social Marketers Front Row Campaign Access With BuddyBrain
10
Sep
 Buddy Media has for some time been acting as a multi-faceted guide to businesses in an online setting that increasingly calls for investment in social integration and social marketing. The company has done everything from managing fairly common-seeming advertising campaigns to developing social applications. Today it unveiled a service called BuddyBrain for “app-vertisers†to more closely observe and manage intel emerging from campaigns conducted in the social realm.
Buddy Media has for some time been acting as a multi-faceted guide to businesses in an online setting that increasingly calls for investment in social integration and social marketing. The company has done everything from managing fairly common-seeming advertising campaigns to developing social applications. Today it unveiled a service called BuddyBrain for “app-vertisers†to more closely observe and manage intel emerging from campaigns conducted in the social realm.

BuddyBrain is segmented into four main quadrants: project center, intelligence center, reference tools, and social wire. A dashboard offering a view of information culled from each sector acts as a sort of welcome screen to one’s account. Naturally, active projects are shown with especial prominence on the page. And beneath the surface, data provided by most every component held within the application is elegantly presented. Details have been well attended to.
The company is issuing this command center as a kind of organizational utility. Better to grasp the workings of the social application space, observe media chatter, maintain focus on the ABCs of project development and execution. And also to, in the words of CEO Michael Lazerow, “entice more brands to make the leap into social advertising and to better service our existing clientele†by keeping to an order of accountability and results. Of course, any reasonable intimation of the marketing space will regard such attentions as crucial. The purpose of BuddyBrain is really to wrap several pieces into one streamlined setup.


In addition to its case-by-case, client-by-client analysis, Buddy Media says the utility’s analysis also makes evident some broad, industry-wide findings. The company provides as an example an aggregate reading of its own most popular “app-vertisement†campaigns:
140,000 installs within 30 days of the start of a campaign;
Those users interacting with said applications spend roughly 2 and 1/2 minutes with each, a time span clearly assessed to be far greater than banner ads and television spots;
85% of users returned for more time spent, and over half returned semi-regularly within 30 days of installation.
We spoke yesterday about media and business and its growing role in the social sphere online - and how various specialists are catering services to the branded world to better connect to citizens of the cloud. Buddy Media is no doubt striving to bring more parties to the table and for those parties present to engage at higher levels still. Its resume includes brands such as Anheuser Busch, Fox, HBO, Microsoft, and Facebook, and ad agencies OmnicomGroup, Universal McCann, JWT and WPP. And it seems safe to presume BuddyBrain, having availed users this palette of applications, will only catalyze growth further.
---
Related Articles at Mashable - All That's New on the Web:
Buddy Media Acquires Five Popular Facebook Apps
Facebook Application “Crushes†Acquired by Buddy Media
Making Facebook Apps Continues to Pay Off for Buddy Media
Buddy University: Attack of the Facebook Clone
30Boxes Launches Flash Buddy Cards
Badongo Offers Buddy Upload Tool for Mac
Sprout Raises $5 Million For Web-Based Flash Creation Tools